本文為Voyage公司Oliver Cameron分享的一篇文章,他認為深度學習對感知能力進步讓無人駕駛有了很大的進步,而無人駕駛的下一個飛躍可能是預測能力。
深度學習對目標檢測算法的提升
在過去的十年中,自動駕駛機器學習社區中的大多數話題都集中在目標檢測上。 如何提高自動駕駛汽車對所有動態物體的檢測和跟蹤能力? 2010年,在深度學習變得很常見之前,感知是自動駕駛汽車功能的主要限制。一輛汽車具有如此高的誤報率和誤報率是不可接受的。ImageNet分類準確度可以很好地說明這一點,最新的解決方案在2010年的準確度僅為50%(今天是88%)。 盡管ImageNet分類與對象檢測方面的最新技術并不能一一列舉,但它確實可以作為計算機視覺技術進步的象征。
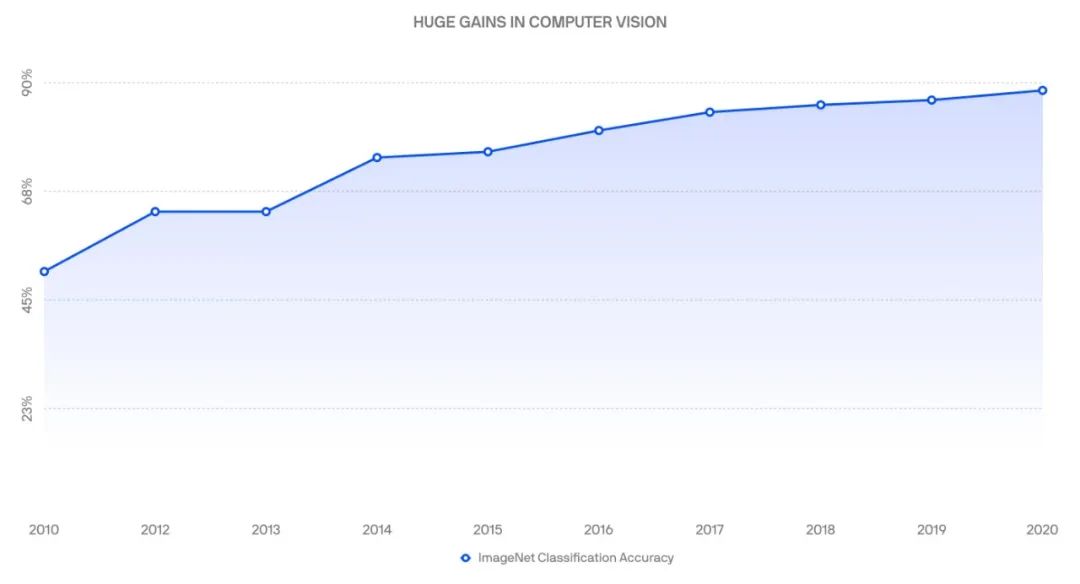
兩年后的2012年,AlexNet成為ImageNet競賽的第一批參賽者之一,該競賽利用了深度學習和卷積神經網絡。自2012年在ImageNet上獲得最先進的準確性之后,AlexNet可能是計算機視覺中最具影響力的論文。
無論是應用于激光雷達,相機還是雷達的深度學習技術,都在2014年左右開始滲透到無人駕駛技術中。
如今,用于感知的深度學習在自動駕駛汽車中已司空見慣,因此,我們繼續看到性能的驚人提升。 近年來,諸如VoxelNet,PIXOR和PointPillars之類的網絡推動了我們在計算機視覺方面的思考。盡管我們絕不應該假設機器人已經獲得了完美的感知,但是計算機視覺的最新發展已經發生了巨大變化,以至于它現在可以說不是自動駕駛汽車商業部署的主要障礙。
注意,以上陳述是基于具有多種傳感器模式的自動駕駛汽車,其中包括飛行時間傳感器,該傳感器返回物理準確的深度信息以饋入您的感知模型。 抱歉,特斯拉!
既然感知不是自動駕駛的大火,那么下一步是什么? 預測!
預測的藝術
現在我們可以安全地檢測到周圍的關鍵物體,所以必須預測它們下一步將要做什么。正確的預測意味著我們將在正確的時間執行正確的操作,同時考慮到周圍人的行動。錯誤的預測意味著我們可能會陷入危險的境地。作為人類,我們使用數千個環境輸入直觀地執行此預測。
預測問題對于無保護的左轉彎最困難實例至關重要。無人駕駛汽車必須在執行轉彎之前預測其周圍所有動態代理的未來動作,這項任務比自動駕駛中的其他問題需要更多的智能。人類駕駛員盡管不是十全十美,但在很大程度上依靠通用情報,真實世界的駕駛經驗和社交線索(例如輕推或手動信號)來成功執行不受保護的左轉彎。

盡管機器比人類具有明顯的優勢(例如360°遠程視野),但與人類相比,自動駕駛技術中的傳統預測可能是非常原始的:
1.感知模塊會在自動駕駛汽車的一定半徑內輸出一組物體檢測結果(例如車輛,行人),然后將其輸入到預測模塊中;
2.然后預測模塊會使用當前(例如方向,速度)和以前的觀察結果來生成有關每個目標在接下來的5秒鐘內可能做什么的單獨預測;
3.通過將所有這些單獨的預測輸入算法,就可以得出關于自動駕駛汽車可以執行的最安全動作的假設;
4.自動駕駛開始執行規定的操作并每100毫秒重新評估該決定。
我們可以想象這種機器人方法會導致不舒適甚至潛在的危險駕駛行為,尤其是在密集的城市環境中。在過去的幾年中,我們看到了深度學習預測方法的實現爆炸式增長。這些方法有可能顯著提高預測的準確性,將其從機器人轉換為類似人類的預測。
用數據驅動的方法解決這些原始的預測,與在深度學習中如何取代深度學習在2010年代中期極為相似。
企業預測研究實例
這是一些實際的例子。
克魯斯(Cruise)的感知工程經理曾就他們如何將預測作為分類問題進行了精彩的演講。
Uber在DRF-Net上分享了他們的工作,該DRF-Net增強了行人的預測能力:“廣泛的實驗表明,我們的模型優于幾個強基準,表現出高可能性,低誤差,低熵和高多模態。 DRF-NET離散預測的強大性能對于基于成本的受限機器人計劃非常有前途。”
蘋果公司發表了一篇名為“最壞案例政策梯度”的新穎的強化學習論文:“構建智能系統的主要挑戰之一是開發在復雜環境中做出可靠,安全的順序決策的能力。”
isee在CVPR 2019上發布了他們關于學習的預測方法的工作:“這種MAT編碼自然可以處理具有不同數量的代理的場景,并通過與代理數量成線性關系的計算復雜性來預測場景中所有代理的軌跡,在MAT上進行卷積運算。”
盡管預測尚未達到所需的性能,但我們將看到數據驅動方法在預測性能方面的巨大飛躍,其方式與深度學習對經典感知的影響非常相似。這些即將到來的飛躍將極大地改善自動駕駛汽車的決策,從而為乘客提供更安全,更順暢的乘車體驗。